Elemente de Combinatorica 2.0
autor: Bogdan Iordache
Inainte de a parcurge acest material va recomand sa consultati articolul introductiv de aici.
Invers Modular
Incepem cu cateva notatii utile. Fie si doua numere intregi, iar un numar natural nenul. Folosim notatia cu semnificatia ca restul impartirii numarului la este egal cu restul impartirii numarului la .
Pentru un numar intreg si natural nenul, definim inversul modular al lui in raport cu , notat cu , ca fiind un numar natural din invervalul cu proprietatea ca: .
Determinarea inversului modular este utila in momentul in care vrem sa determinam restul impartirii la al unei formule care implica operatii de impartire. Spre exemplu, fie si doua numere intregi, cu proprietatea ca . Presupunem ca si sunt resturile impartirii lui , respectiv la . Cunoscand si vrem sa determinam restul impartirii numarului la (il vom nota cu ). Aceasta problema o putem rezolva astfel:
.
Tot ce trebuie sa facem este sa inmultim restul lui () cu inversul modular al lui (care este usor de vazut ca este si inversul modular al lui ).
Obs. Nu intotdeauna inversul modular exista. De exemplu, care este inversul modular al lui in raport cu ? Nu exista niciun numar pe care l-as putea inmulti cu astfel incat sa obtin un multiplu de plus . O conditie necesara ca un numar sa accepte invers modular in raport cu este ca (sa fie prime intre ele). Dem: Presupunem ca accepta invers modular, notat cu , notam cu . Avem ca (divide un multiplu de plus ). Dar , obtinem prin scaderea ultimelor doua relatii ca , deci singura optiune este .
Conditia demonstrata mai devreme este necesara ( si trebuie sa fie prime intre
ele pentru a gasi invers modular), dar este oare si suficienta (daca si sunt prime intre ele, avem
invers modular pentru )? Raspunsul este
da, si reiese usor din Teorema lui Euler:
daca ; unde este “indicatorul lui Euler” definit
ca numarul de numere naturale mai mici decat care sunt prime cu .
Rescriind formula de mai sus putem extrage o formula pentru ,
anume:
.
Obs. daca este prim, din moment ce , Teorema lui Euler ne da aceeasi relatie ca Mica Teorema a lui Fermat: , oricare ar fi prim si numar natural nedivizibil cu .
Cum calculam ?
Fie
descompunerea in factori primi a lui . Indicatorul lui Euler
poate fi calculat astfel:
.
Pentru un oarecare putem determina in descompunerea in factori primi a acestuia si sa calculam indicatorul cu formula de mai sus. Daca vrem sa aflam indicatorul pentru mai multe numere, de exemplu pentru toate numerele naturale mai mici sau egale cu , putem apela la o metoda de tip ciur:
for (int i = 1; i <= N; ++i)
phi[i] = i;
for (int i = 2; i <= N; ++i) {
if (phi[i] == i) { \\ phi[i] nu a fost modificat, i este prim
for (int j = i; j <= N; j += i)
phi[j] = phi[j] / i * (i - 1);
}
}
Cum calculam ?
Pentru a calcula avem de determinat restul impartirii lui la . Acest lucru poate fi facut usor folosind exponentiere in timp logaritmic (complexitate :
int log_pow(int a, int n, int mod) {
// calculeaza a^n % mod
int res = 1;
while (n) { // scriem n in baza 2
if (n % 2 == 1) // daca bitul curent este 1
res = (res * a) % mod; // inmultim la rezultat puterea de forma a^(2^k)
n /= 2;
a = (a * a) % mod; // iteram prin a, a^2, a^4, a^8, ...
}
return res;
}
Daca cunoastem phi_m, indicatorul lui Euler pentru , implementarea inversului
modular se reduce la:
int inv_mod(int a, int m, int phi_m) {
return log_pow(a, phi_m - 1, m);
}
Calculul formulelor combinatorice
Am vazut in articolul anterior cum calculul formulelor pentru combinari, aranjamente, etc. are ca principala dificultate evitarea impartirilor de factoriale. Putem acum sa ne folosim de notiunea de invers modular. Mai intai precalculam toate factorialele de care am putea avea nevoie:
fact[0] = 1;
for (int i = 1; i <= N; ++i)
fact[i] = (i * fact[i - 1]) % MOD;
Putem calcula acum inversele modulare ale acestor factoriale. Putem eficientiza procesul folosindu-ne de faptul ca :
inv_fact[N] = inv_mod(fact[N], MOD, phi_MOD);
for (int i = N - 1; i; --i)
inv_fact[i] = (i + 1) * inv_fact[i + 1] % MOD;
Putem acum, spre exemplu, sa calculam astfel:
int comb_i_j = fact[i] * inv_fact[j] * inv_fact[i - j] % MOD;
Obs. Pentru a putea calcula aceste inverse modulare trebuie ca sa fie prim cu toate factorialele precalculate. Deobicei, in probleme, este un numar prim , ceea ce garanteaza aceasta restrictie. Daca nu este valabila aceasta conditie, se pot face diverse artificii pentru a precalcula factorialele ignorand factorii primi din descompunerea acestora care il divid pe , si calcularea separata a exponentilor acestora, puteti gasi o interpretare a acestei idei aici.
Problema 1 (Nozero)
Observația principală care ne duce la rezolvarea problemei este că numărul K este mic în comparație cu numărul total de permutări de ordin (). De aceea pentru orice și orice , primele poziții vor fi fixate (avem valoarea egală cu poziția) și doar ultimele cel mult valori vor fi permutate.
Astfel ajungem la următoarele subprobleme:
Subproblema 1: determinam a -a permutare în ordine lexicografică de dimensiune cel mult (notăm această dimensiune cu ). Această subproblemă se poate rezolva în mai multe moduri întrucât lungimea permutărilor este mică. O variantă ar fi să încercăm să fixăm pe rând de la stânga la dreapta valorile. Pentru poziția încercăm în ordine crescătoare toate valorile care nu au fost puse încă, dacă o fixăm pe aceasta știm că elementele din dreapta ei pot fi permutate în moduri. Dacă numărul de moduri în care mai putem permuta ultimele valori este mai mic decât , scădem din acest număr și încercăm o valoare mai mare pe poziția . La final vom avea toate valorile setate, iar K = 0.
Subproblema 2: determinarea numărului de valori care conțin cifra și sunt mai mici sau egale decât un P
dat. Deoarce știm că primele aproximativ valori (al căror număr îl vom nota cu
) sunt egale cu poziția lor
din permutare, este suficient să număram câte dintre aceste valori conțin . Pentru un număr de cifre fixat avem
valori de cifre care nu conțin cifra
. Cu această relație numărăm toate
valorile care au numărul de cifre strict mai mic decât numărul de cifre ale lui .
Mai avem de numărat valorile care au același număr de cifre cu si nu conțin . Fiind mai mici decât și având același număr de
cifre, putem grupa aceste valori după lungimea celui mai lung prefix pe care îl au în comun cu . Dacă acest prefix conține
0 nu avem ce număra, iar dacă nu, vedem câte cifre nenule mai mici strict decât cifra de pe poziția imediat
următoare prefixului din există, iar pentru fiecare
din aceste variante celelalte cifre pot fi fixate cu oricare dintre cele valori nenule posibile.
Din cele două subprobleme putem determina câte poziții sunt valide (poziția nu conține cifra si valoarea de la acea poziție nu conține ).
Teorema lui Lucas
Fie un numar prim. Vrem sa calculam (unde ). Observati ca nu am dat nicio restrictie suplimentara pentru si , deci aceste valori pot fi mai mari decat . Ne lovim deci de problema enuntata mai devreme, in care nu putem calcula direct inversele modulare ale factorialelor, intrucat acestea pot fi divizibile cu .
Teorema lui Lucas ne vine in ajutor. Mai intai scriem numerele si in baza :
;
Conform teoremei avem:
cu conventia ca , daca .
poate fi calculat usor, intrucat formula sa depinde de factoriale , care sunt deci prime cu .
Problema 2 (Jap2)
Aceasta problema se poate rezolva usor folosind direct Teorema lui Lucas.
Pentru o alta varianta de rezolvare, care se poate generaliza si la calculul de aranjamente, puteti consulta
descrierea oficiala.
Problema 3 (Nmult)
Plecam de la faptul ca .
Realizam urmatoarea “schimbare de variabila”: .
Avem deci o bijectie (corespondenta una-la-unu) intre sirurile corecte
si sirurile ,
cu .
Am redus problema la a determina “cate siruri strict crescatoare de numere naturale din intervalul exista”. R: .
Intrucat aceste combinari trebuie calculate modulo (numar prim), iar , trebuie sa folosim teorema lui Lucas pentru a calcula combinarea.
Numere Catalan
Numerele catalan se noteaza cu si se calculeaza dupa formula .
Acestor numere le este asociata o multime variata de clase de probleme care se reduc la calcularea formulei specificate. Enumeram doar cateva dintre acestea.
a. Numarul de siruri corecte de paranteze
Consideram un sir de caractere, in care caractere sunt ‘’, iar celelalte sunt ‘’. O parantezare corecta este un astfel de sir care respecta urmatoarea definitie recursiva:
- sirul vid este o parantezare corecta
- daca si sunt parantezari corecte, concatenarea lor este o parantezare corecta
- daca este o parantezare corecta, atunci este de asemenea o parantezare corecta.
Exemplu: , , sunt parantezari corecte, in timp ce , nu sunt.
Numarul de parantezari corecte de lungime este .
b. Numarul de drumuri monotone in spatiu laticeal care nu depasesc diagonala principala
Consideram un spatiu laticeal (craoiaj) de dimensiune . Pornim din punctul si dorim sa ajungem in facand pasi de lungime unitate fie in sus, fie la dreapta, cu conditia ca niciodata sa nu depasim diagonala principala, adica sa nu ajungem intr-un punct cu . Cate astfel de drumuri se pot forma? R: .
Avem mai jos toate drumurile posibile pentru :

c. Numarul de arbori binari stricti
Un arbore binar strict este un arbore in care toate nodurile interne (care nu sunt frunze) au exact fii. Pentru un arbore binar strict cu noduri interne vom avea mereu frunze. Numarul de arbori binari stricti cu noduri interne este .
Pentru avem urmatorii arbori:

d. Numarul de triangulari ale unui poligon convex
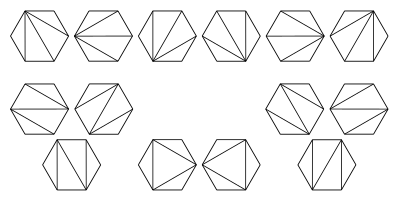
O triangulare a unui poligon convex reprezinta o modalitate de a trasa diagonale ale acestuia care nu se intersecteaza (cu exceptia capetelor) cu scopul de a imparti suprafata acestui poligon in triunghiuri. Pentru un poligon convex cu laturi avem triangulari.
Triangularile pentru un hexagon sunt urmatoarele:
Demonstratia formulei
Putem demonstra pentru oricare dintre problemele de mai sus ca numarul de posibilitati este , apoi sa demonstram ca aceste probleme sunt echivalente intre ele. Vom schita pe scurt demonstratia ca numarul de drumuri sus-dreapta, care nu depasesc diagonala principala intr-un caroiaj de este . Pentru alte demonstratii puteti consulta articolul de pe Wikipedia.
Putem porni de la a numara toate drumurile sus-dreapta de la la . Acestea sunt in total (orice astfel de drum trebuie sa contina pasi in sus si pasi la dreapta, interclasati in orice mod posibil).
Trebuie sa scadem acum drumurile care depasesc diagonala principala. Pentru a le numara pe acestea folosim urmatoarea metoda: fie un astfel de drum “gresit”, consideram primul punct de pe drum de forma cu (prima oara cand drumul depaseste diagonala principala). Numim diagonala critica, diagonala paralela cu cea principala aflata cu o unitate deasupra acesteia, evident se afla pe diagonala critica. Aplicam o reflexie a sufixului drumului incepand de la fata de diagonala critica. Obtinem astfel, in final, un drum de la la .
Exemplu de reflexie:
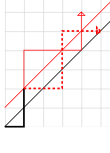
Este usor de vazut ca avem o bijectie de la drumurile “gresite” catre toate drumurile de la la . Un drum oarecare de la la va trece cu siguranta peste diagonala principala si aplicand din nou operatia de reflexie ajungem la drumul “gresit” corespunzator. Obtinem astfel ca avem drumuri “gresite”.
In final, .
In continuare, vom da cateva exemple de demonstratii de echivalenta:
i) drumuri sus-dreapta sub diagonala principala siruri corecte de paranteze
Pornim de la urmatoarea observatie, un sir de paranteze este corect daca si numai daca:
- numarul de paranteze deschise este egal cu numarul de paranteze inchise
- pentru orice prefix, numarul de paranteze deschise este mai mare sau egal cu numarul de paranteze inchise
Putem construi acum urmatoarea bijectie: pentru un drum, marcam toti pasii la dreapta cu si toti pasii in sus cu . Intrucat drumul nu depaseste diagonala principala, pentru niciun prefix nu vom avea mai multe drumuri in sus decat la dreapta, deci orice sir de paranteze astfel obtinut este corect.
ii) siruri corecte de paranteze arbori binari stricti
Intr-un arbore binar strict, odata fixata configuratia nodurilor interne, pozitia frunzelor este unic determinata. Putem realiza o bijectie intre parantezari si arbori astfel:
- consideram prima paranteza deschisa si perechea sa (paranteza care “o inchide”): obtinem parantezarea
- desenam radacina arborelui, apoi construim recursiv subarborele stang si pe cel drept
- subarborelui stang ii asociem sirul de paranteze
- subarborelui drept ii asociem sirul de paranteze
Folosind procedeul de mai sus obtinem configuratia nodurilor interne, ramane doar sa mai adaugam si frunzele
(un singur mod posibil). Pentru arborii din figura de mai sus, parantezarile asociate ar fi, in ordine:
Problema 4 (Catalan)
Simpla implementare a formulei numerelor Catalan.
Problema 5 (Puteri3)
Reamintim binomul lui Newton:
Folosim urmatoarea notatie mai generala: .
Substituim cu :
Obtinem formula pentru :
Am obtinut deci o recurenta pentru bazata pe . Tinand cont ca , putem determina in .
Problema 6 (Shgraf)
Definim numarul de shgrafuri cu noduri, etichetate folosind
etichete distincte. Un
shgraf poate avea mai multe componente conexe, a caror ordine nu conteaza. Una dintre aceste componente
conexe va contine nodul cu cea mai mare eticheta. Putem fixa dimensiunea acestei
componente. Restul etichetelor din aceasta componenta pot fi alese in
moduri. Obtinem recurenta:
Am notat cu numarul de shgrafuri
conexe cu noduri, etichetate folosind
etichete distincte. Pentru
a numara aceste shgrafuri observam mai intai ca structura lor corespunde unui ciclu de care sunt “agatati”
arbori cu radacina in nodurile ciclului. Pentru , numarul de astfel de grafuri cu
noduri, putem fixa mai
intai structura ciclului. Putem fixa dimensiunea acestuia, avem
la dispozitie
moduri de a eticheta acest ciclu (alegem etichete si le permutam pe
un ciclu de lungime ). Obtinem recurenta:
Am notat cu numarul de moduri in care putem
organiza noduri in arborii “agatati”
de un ciclu cu noduri, etichetandu-le cu
etichete distincte. Ciclul
de noduri este deja fixat si
etichetat, deci putem stabili o ordine a nodurilor de pe ciclu. Incercam sa fixam acum cate noduri vor fi
agatate intr-un arbore cu radacina in ultimul nod de pe ciclu. Fie numarul acestora, putem sa
le etichetam in
moduri. Ramane acum sa determinam cati arbori etichetati cu noduri exista ( nodurile alese, plus
ultimul nod de pe ciclu). Numarul acestor arbori este
(pentru demonstratie studiati Codurile
Prüfer). Obtinem recurenta:
Problema ne cere sa ignoram acele shgrafuri care au cicluri de lungime mai mica decat . Putem “repara” recurenta pentru considerand doar . Obtinem complexitatea finala .
Problema 7 (provocare)
Pornim de la urmatoarea observatie: putem asocia fiecarui nod din arbore un sir de caractere de forma “aabbab” care descrie secventa de muchii de la radacina arborelui pana la acel nod. Evident, pentru oricare doua noduri distincte din arbore, sirurile de caractere asociate sunt diferite.
Vom incerca sa cautam binar inaltimea arborelui. Pentru o inaltime fixata numaram cate secvente de caractere corespund unei lungimi mai mici decat aceasta inaltime. Lungimea se calculeaza ca (unde si sunt numerele de caractere “a” si “b” din secventa, si au semnificatia din enunt). Daca numarul de astfel de secvente este mai mic decat , inseamna cu certitudine ca inaltimea arborelui trebuie sa fie mai mare (“nu incap toate nodurile in aceasta inaltime”), daca numarul este vom incerca o inaltime mai mica.
Stiind ca avem caractere “a” si caractere “b”, putem genera
secvente. Numarul pe care incercam sa il determinam, pentru o inaltime fixata () in cautarea binara,
este:
Presupunem, fara a restrange generalitatea, ca . Daca fixam , valoarea maxima pentru
este . Deci pentru fixat adunam la numarul
posibil de noduri:
.
Pentru a restrange expresia de mai sus, vom incerca o interpretare intuitiva a formulei. Amintim formula
“stars and bars”: numarul de moduri de a imparti bile identice in cutii diferite. Schimband
notatiile
reprezinta numarul de moduri de a distribui bile identice in cutii diferite. In concluzie, suma de
mai sus se traduce in “cate moduri de a distribui cel mult
bile identice in cutii diferite” exista. Dar acest
lucru este echivalent cu a numara in cate moduri putem imparti
bile in cutii (ultima cutie reprezinta bilele
“aruncate”). Obtinem formula restransa:
.
Ultima optimizare vine din observatia ca foarte multe din combinarile de mai sus au valori mari. Pentru si , avem . Deci daca ajungem la o astfel de combinare in timpul calculului, putem sa il oprim si sa stabilim ca inaltimea fixata este mai mare sau egala cu cea cautata.
Complexitatea finala va fi aproximativ , unde este numarul de combinari care trebuie precalculate (in jur de ).
Relatii de recurenta. Calcul matriceal
Problema 8 (KFib)
Problema ne cere sa determinam al -lea termen al sirului Fibonacci (). Consideram urmatorul vector cu elemente: , continand doua numere consecutive din sirul Fibonacci. Printr-o inmultire cu o matrice de dimensiune , putem obtine vectorul continand termenii si .
Folosind proprietatea de asociativitate a inmultirii de matrici obtinem:
Putem determina deci in complexitate folosind metoda de ridicare la putere in timp logaritmic a matricei patratice. O implementare a acestei idei o puteti accesa aici.
Problema 9 (Iepuri)
Notam cu
numarul de iepuri din ziua .
, ,
Construim matricea
Avem:
Putem sa aplicam inca o data ridicarea la putere in timp logaritmic pentru formula:
Problema 10 (Ecu)
Trecerea de la valorile de la iteratia : () la valorile de la itaratia : () se poate face printr-o inmultire cu o matrice de dimensiune .
Aplicand ridicare la putere in timp logaritmic obtinem complexitatea . Termenul vine de la complexitatea de a inmulti doua matrici de dimensiune .
Problema 11 (Recurenta2)
Notam . Recurenta pentru .
Il putem explicita pe
in functie de termenii anteriori:
.
Putem organiza aceasta recurenta folosind urmatoarea matrice:
Putem sa determinam
in folosind exponentiere in timp
logaritmic de matrice.
Principiul includerii si excluderii
Fie multimi finite. Principiul includerii si excluderii cuprinde urmatoarele identitati:
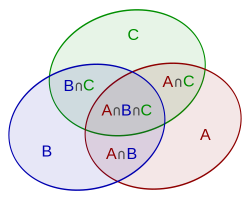
Problema 12 (Pinex)
Problema este o aplicatie simpla a principiului includerii si excluderii.
Fie
divizorii primi ai lui .
Notam cu (multimea numerelor mai mici decat
, divizibile cu ).
Fie , este prim cu , adica , daca si numai daca , nu este divizibil cu . Putem deci observa ca numarul de numere prime cu mai mici decat este:
Dar putem calcula folosind principiul includerii si excluderii. Pentru aceasta trebuie sa stabilim care este cardinalul unei intersectii oarecare de astfel de multimi. Fie , , care este cardinalul multimii ?
Ce inseamna ca un numar se afla in multimea ? Inseamna ca se divide cu , dar toate aceste valori sunt numere prime, deci se divide si cu .
Cate numere se divid cu un numar ?
Avem deci: .
Sirurile de indici , pot fi generate in folosind backtracking sau iterand prin toate numerele cu biti, urmand ca pentru o configuratie cardinalul intersectiei sa fie calculat in . Cum numarul de numere prime distincte care il divid pe este mic, solutia se incadreaza fara probleme in timp.
Problema 13 (Indep)
Notam cu sirul
din enunt.
Notam cu valoarea maxima din ().
Notam cu (multimea numerelor din divizibile cu ).
Notam cu , numarul de subsiruri nevide ale lui
in care toate elementele
sunt divizibile cu .
Fie
toate numerele prime mai mici decat .
Un subsir al lui are cmmdc-ul daca si numai daca
exista un element al subsirului care nu este divizibil cu .
Folsind principiul includerii si excluderii, observam ca numarul cautat de subsiruri este:
O complexitate de ar fi prea mare pentru a obtine raspunsul. Insa observam ca ne intereseaza doar pentru . Cu alte cuvinte ne uitam la toate numerele din intervalul care se scriu ca produs de numere prime distincte. Daca se scrie ca un produs de un numar impar de numere prime distincte scadem din raspuns , iar daca se scrie ca un produs de un numar par de numere prime distincte adunam la raspuns.
Ca o ultima observatie, intrucat , numerle pot depasi orice tip intreg din C++, deci avem nevoie sa mentinem folosind numere mari.
Problema 14 (Cowfood)
Numarul de experimente cautat il vom putea calcula ca , unde reprezinta numarul total de experimente valide (valide in legatura cu limita ), iar reprezinta numarul de experimente valide care sigur vor esua.
Pentru un experiment notam multimea experimentelor care vor esua conform experimentului . Astfel pentru un experiment , toate experimentele cu apartin multimii .
Observam ca , unde
sunt experimentele din input.
Folosind principiul includerii si excluderii: .
Ce inseamna intersectia in acest context?
Daca si sunt doua experimente,
corespunde multimii experimentelor care vor esua atat conform lui cat si conform lui , echivalent cu a considera
experimentele care vor esua conform experimentului .
Astfel pentru a calcula formula putem folosi backtracking pentru a genera toate submultimile de experimente din input si a reduce aceasta submultime la un singur experiment echivalent.
Ramane sa stabilim cum putem calcula pentru orice experiment . Pentru a obtine un experiment esuat putem incrementa oricare dintre valorile atata timp cat suma lor nu depaseste . Deci putem realiza cel mult astfel de incrementari. Este echivalent cu a numara “in cate moduri pot distribui cel mult bile identice in cutii diferite”.
Am vazut la problema Provocare cum ca numarul de moduri de a distribui cel mult bile identice in cutii diferite este egal cu numarul de moduri de a distribui exact bile identice in cutii (ultima cutie reprezinta bilele pe care le “aruncam/ignoram”). Acest lucru se poate calcula folosind “stars and bars”: .
Pentru a determina , numarul total de experimente valide, putem determina , unde , adica cate experimente esueaza conform experimentului cu toate valorile (toate experimentele esueaza in acest caz).
Complexitatea asteptata este .